
Tech Tips
SQL - Comparing multi-table query styles - Part 1
Let's take a look at INNER JOINs, Correlated Subqueries, Derived tables and CROSS APPLY for joining table data in SQL.
SQL Queries to Retrieve Records from Multiple Tables
Relational databases store data in tables and we can retrieve information with SQL SELECT statements accessing one or more tables.
Sometimes choosing the right method to extract related records can be a challenge. You might be able to think of a number of ways of structuring a query to produce the same set of records, but which method should you use? The answer might come from a couple of considerations:
- Which method is the most efficient and fastest?
- Which method is the easiest to understand, write and maintain?
So what methods can we think of?
- Straight forward table JOIN
- Derived table - simple subquery
- Derived table - correlated subquery
- CROSS APPLY
- Simple subquery - nested in SELECT list and WHERE clause
- Correlated subquery - nested in SELECT list and WHERE clause
- Simple subquery in WHERE clause
- INTERSECT
So let's take a look at some of these options, exploring three join scenarios:
- We need to retrieve/display columns from more than one of the tables involved
- We only need to retrieve/display columns from one of the tables involved
- We are looking for a common set of values between two record sets
We will use the AdventureWorks database on a SQL Server instance for our examples, but the SQL syntax shown is relevant to SQL Server on-premise, Azure SQL, Synapse Dedicated Pool and Fabric Warehouse.
In this first blog of the series we will look at multi-table queries where we need columns from more than one table to be returned in the results set. Part 2 of this series of articles can be found here.
Part 1 – Retrieving values from more than one table
Here are four different style queries to retrieve identical record sets. All of them display all orders along with the name of the sales person that processed the order.
In this instance we wish to retrieve the SalesOrderID and OrderDate from the Sales.SalesOrderHeader table and the name of the sales person from the Person.Person table.
Here are the results returned by each of the following four queries:

Each query has an ORDER BY clause to ensure the records come out in the same order. Without it, although the same records are returned they may be returned in differing orders. Try it and see!
INNER JOIN
The first query uses a simple INNER JOIN joining the person record to the order record via the Primary Key/Foreign Key columns BusinessEntityID and SalesPersonID.
/*Queries where columns are required from both tables*/
--Simple join
SELECT SalesOrderID, OrderDate, FirstName + SPACE(1) + LastName AS "SalesPerson"
FROM Sales.SalesOrderHeader AS sh
JOIN Person.Person AS p ON sh.SalesPersonID = p.BusinessEntityID
ORDER BY SalesPerson, SalesOrderIDDerived Table
The second query uses a derived table to retrieve the Person.Person records. A derived table is a subquery placed in the FROM clause of an outer query. The join condition between the Sales.SalesOrderHeader table and the subquery is positioned after the subquery. The subquery must be given a table name, even though it may not be referenced, which in this example is “p”.
--Derived Table - simple subquery
SELECT SalesOrderID, OrderDate, SalesPerson
FROM Sales.SalesOrderHeader AS sh
JOIN
(SELECT BusinessEntityID, FirstName + SPACE(1) + LastName AS "SalesPerson"
FROM Person.Person
) AS p
ON sh.SalesPersonID = p.BusinessEntityID
ORDER BY SalesPerson, SalesOrderIDCROSS APPLY
The third query implements a CROSS APPLY statement. CROSS APPLY enables a subquery to be evaluated for every record in the table to the left of it. The join condition is placed in the WHERE clause of the subquery.
--CROSS APPLY
SELECT SalesOrderID, OrderDate, SalesPerson
FROM Sales.SalesOrderHeader AS sh
CROSS APPLY
(SELECT BusinessEntityID, FirstName + SPACE(1) + LastName AS "SalesPerson"
FROM Person.Person AS p1
WHERE sh.SalesPersonID = p1.BusinessEntityID
) AS p
ORDER BY SalesPerson, SalesOrderIDCorrelated Subquery
The fourth version has a subquery in the WHERE clause to restrict the results set to the orders handled by a sales person, but because we wish to retrieve the name of the sales person as well as the SalesOrderID and OrderDate, the correlated subquery has also been nested in the SELECT list.
--Correlated Subquery nested in SELECT list and WHERE clause
SELECT SalesOrderID, OrderDate, (SELECT FirstName + SPACE(1) + LastName
FROM Person.Person AS p1
WHERE p1.BusinessEntityID = sh.SalesPersonID
) AS SalesPerson
FROM Sales.SalesOrderHeader AS sh
WHERE sh.SalesPersonID = (SELECT BusinessEntityID
FROM Person.Person AS p1
WHERE p1.BusinessEntityID = sh.SalesPersonID
)
ORDER BY SalesPerson, SalesOrderIDSo Which is the Best?
That’s a good question!
The reality is that often when we write an SQL query the database management system’s Query Optimizer may well simplify or rewrite your query to make it better. This can result in the same execution plan being produced regardless of how you structure your query.
With each version of SQL Server or Oracle the query optimizer gets improved and the simplifications it can make may also be added to.
So am I saying that it doesn’t matter what way you write the query as long as the results are correct? Well no. There are many things that influence whether a query can be simplified and indeed what eventual execution plan will be used. Among the top influencers are:
- The size of the tables involved
- The relative sizes of tables involved
- Columns included in the SELECT list
- WHERE clause conditions included – SARGs or not SARGs
- The use of NOT operators in WHERE clause conditions
- The existence of indexes
(Opportunity for a performance tip here – always limit select lists to just the columns and expressions you require, always specify a WHERE clause when possible, avoid using NOT anywhere in a WHERE clause if possible, create indexes on columns that frequently appear in WHERE clauses.)
Looking at the execution plans implemented for queries enables us to see how our queries were carried out.
Query Execution Plans
The following screen shot shows that the first three of our queries resulted in the same query execution plan, but the fourth one is different and looks to be more efficient – It shows a 15% of batch cost as opposed to 28% shown for the other three.

The first three queries all carry out the following steps:
- Scan of the clustered index (the table) on the SalesOrderHeader table
- Scan of the non clustered index on the LastName and FirstName columns of the Person table.
- A compute of the concatenated sales person’s name
- An INNER JOIN between the SalesOrderHeader records and the Person records
- A sort to return the records in SalesPerson then SalesOrderID order.
Although queries 2 and 3 contain a subquery and a CROSS APPLY respectively they have both been rewritten as a simple INNER JOIN.
The fourth query has a different plan:

The fourth query carries out the following steps:
- Index scan of the non clustered index on the LastName and FirstName columns of the Person table
- A compute of the concatenated sales person’s name
- Index scan of the clustered index on the SalesOrderHeader table
- Index scan of the non clustered index on the the rowguid column of the Person table
- An INNER JOIN between the rowguid index records and the SalesOrderHeader records
- An OUTER JOIN between the LastName FirstName index records and the records resulting from the previous INNER JOIN
- A sort to return the records in SaelsPerson then SalesOrderID order
The statement costs for the fourth query are shown below (a total estimated statement cost of 1.42964):

The reason that this plan seems to be better than the plan used by the first three queries is down to the extra rowguid index that is being used.
CREATE UNIQUE NONCLUSTERED INDEX [AK_Person_rowguid] ON [Person].[Person]
(
[rowguid] ASC
)Indexing Makes a Big Difference
If we drop the rowguid index and run the query again the query comes out at 16% of the batch cost now with a slightly different execution plan:
The plan is virtually identical, but the rowguid index scan has been replaced with a second scan of the LastName FirstName non clustered index.

The statement costs for the fourth query are as follows (a total estimated statement cost of 1.45852):

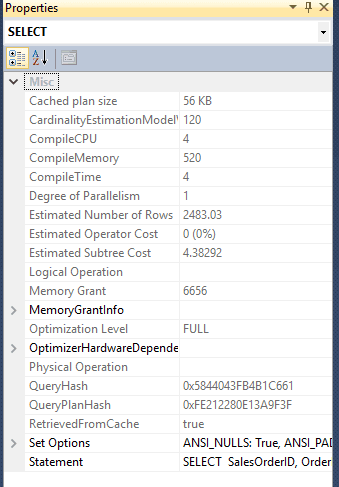
Now we will drop that index too. Although the fourth query still has a different plan the query plan costs are now very similar:

The statement costs for the fourth query are as follows ( an estimated total cost of 4.38292):

As we can see the cost of the plan without indexes is much higher as tables (clustered indexes) need to be scanned rather than the smaller indexes.
While we are looking at execution plan properties, one other thing to note about all three Properties screen shots is that the QueryHash value is the same for all three (same SQL statement), but the QueryPlanHash is different for all three (different plan used).
Conclusion – Choosing the best SQL SELECT statement
What we can see from the examples is that, if we are not concerned about performance, we can structure our multi-table queries in many ways. However, if performance is a concern, then the style of query and the indexes in place can massively impact query plan costs and the time it takes for a query to execute.
The query optimizers employed by SQL Server and Oracle implement a full cost based optimization algorithm to determine which query execution plan will be used. If you can see several ways of producing the same results sets then try them all and compare the plans. You should note though that an optimum plan can be different over time as tables grow/shrink and the distribution or skew of data changes.
There are so many factors that affect query performance and query plan selection – too many to address in this article, but we examine more in Part 2 and Part 3 (coming soon).
I should also point out that there can be execution plan differences between SQL Server (on-premise), Azure SQL, Synapse and Fabric Warehouse. This is because each has a different implementation of the query optimiser.
Execution plans will also be accessed differently and will look different for Fabric Warehouse and Synapse dedicated pools.
Do you need help in tuning poorly performing queries?
PTR offers consultancy, training and blended solutions in SQL Server performance tuning. Take a look at our SQL Server Performance & Tuning course. Or give us a call if you think we can help you with our consultancy service.
MD
Mandy Doward
Managing Director
PTR’s owner and Managing Director is a Microsoft certified Business Intelligence (BI) Consultant, with over 35 years of experience working with data analytics and BI.
Related Articles
Frequently Asked Questions
Couldn’t find the answer you were looking for? Feel free to reach out to us! Our team of experts is here to help.
Contact Us